Welcome to the very first post in a new blog! Here I will discuss software development, SRE work, and other fun stuff. Sometimes an idea is just too good to pass up. I hope this blog will motivate me to turn sparks and little pieces into general knowledge in writing the words down.
The other day I was discussing Tabby with a coworker. We talked about whether we should consider AI-autocompleted code harmful and ditch everyone’s newfound habit due to LLM’s inherent unreliability and their tendency toward spaghetti code, throwing traditional software engineering principles like DRY out the window. I disagreed: what if we could have a framework that integrates AI development tooling while also making everything better and more reliable instead? This instantly reminds me of Test-Driven Development, or TDD, which I think is great when combined with the use of a Large Language Model.
TDD in essence is to write comprehensive unit tests before you work on the main program. Since you wrote so many test cases that they essentially become the full specification, having the tests pass at the end “proves” your program’s correctness. Despite its promise, a lot of people find it a ridiculously clumsy process, even a major drag on productivity. Days could pass when nothing useful gets done. LLMs, however, have fundamentally changed the economics of doing TDD.
How I normally code with an LLM
I used tools like Github Copilot heavily ever since they came along. They are good for finding patterns and filling in the next few lines, but usually struggle to: look at a clear specification, think deeply about it, and produce a whole working module against said specification. Sometimes a problem is so easy I am positive Copilot must be capable of it, but it stops short of giving me the full solution, opting to generate a single line of code instead.
To achieve what I want, LLMs need to be given well-formed requests with necessary, but not overwhelming, contexts. Stuff every tool and library at our disposal inside a model’s context, then it is distracted and easily carried away from the specific task at hand.
In the end, I find myself rephrasing and renaming project-specific things in more general terms, introducing additional pieces of context into the conversation only when I realize solving the task requires them after all.
Another observation I had working with LLMs is that they are great debuggers. I can often paste raw error outputs to an LLM, and more often than not, they succeed at guessing the cause.
At some point, I realized that the bulk of the friction coding with an LLM came from the back-and-forth copy-pasting juggle between my IDE, shell terminal, and the chat interface.
Can I automate it?
So I wrote a little event loop to automate this process.
In the first prompt we give to the LLM, we type in a specification of the function we want to implement and a function signature for extra stability. The LLM is expected to generate a good unit test followed by an implementation.
Let’s give it a non-trivial, real-world problem to be solved:
% go run main.go \
--spec 'develop a function to take in a large text, recognize and parse any and all ipv4 and ipv6 addresses and CIDRs contained within it (these may be surrounded by random words or symbols like commas), then return them as a list' \
--sig 'func ParseCidrs(input string) ([]*net.IPNet, error)'
The model will happily give us a first draft, which we immediately parse and load into a “sandbox” subdirectory for automatic verification:
% tree ./sandbox
./sandbox
├── go.mod
├── go.sum
├── main.go
└── main_test.go
go mod tidy && gotfmt -w . && goimports -w . is used to fix minor syntax issues, then go test . -v is run.
If things fail (totally expected at this point,) we make use of the second (iteration) prompt. Now that we are working on existing code, this prompt includes the code we just ran and, crucially, the command line output from running the test, which would be either a compiler error or information about some failed tests. The model is expected to think about what happened and iterate by producing a revised test + implementation in a loop until all tests are cleared.
The idea is that in most cases, sending the full debug session is not a very frugal use of the model’s context. A reasonably intelligent model can think about what went wrong and make incremental changes. We also get the benefit of way lower API bills by keeping the context length more or less constant, regardless of how many iterations we end up doing.
Sometimes the model does get stuck. In our CIDR example, claude-3.5-sonnet came very close to all-clear on its second attempt, but proceeded to fail the same test case twice in a row. This is when I come in to look at the code, realize the regexp is not matching until the final ‘1’ in “2001:db8::1”, provide that as an explicit hint to the model:
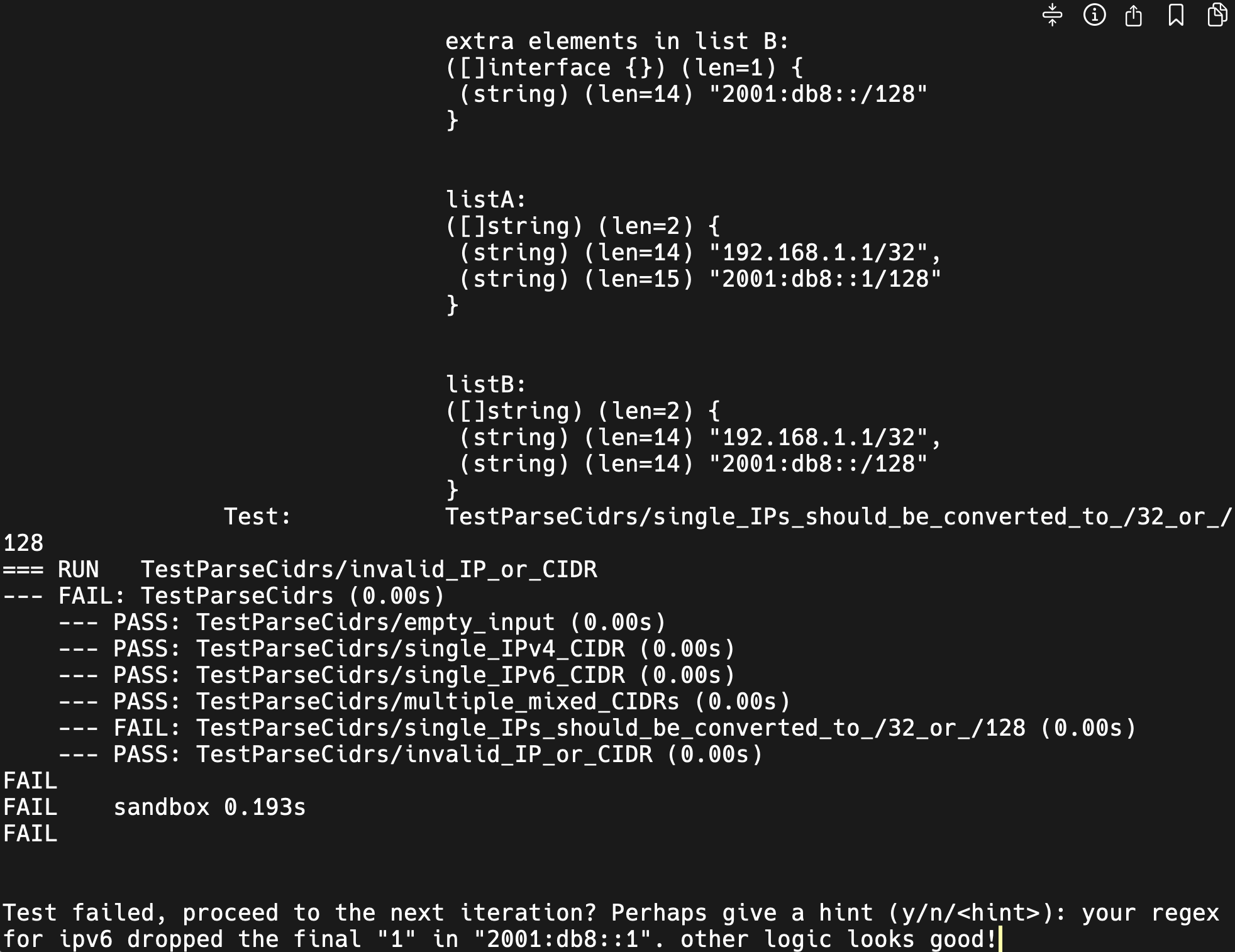
Claude makes progress and clears the tests with our help:

Now we contend with the “who guards the guard” problem. Because LLMs are unreliable agents, it might so happen that Claude just scammed us by spitting out useless (or otherwise low-effort) test cases. Anyway, it is a good practice that whoever implements the code shouldn’t write their own tests, because the same blindspots in design will crop up in tests. In our case, LLM generated both. So it’s time to introduce some human input in the form of additional test cases, which is made extra convenient since the model already provided the overall structure of our test. If those cases pass, we can be reasonably confident in integrating this function into our codebase. Theoretically, you might even invoke a third prompt to do some AI-powered mutation testing by asking for a subtle, but critical, change in the implementation that is supposed to break our tests, then find out if it did!
LLM-powered development and cognitive load
So this method appears to reliably tackle leetcode-style questions, but would it work in a practical codebase with an actual dependency graph? I believe it can be made to work with some engineering effort, and it’s great news for the codebase’s long-term maintainability if you do. For best results, our project structure needs to be set up with LLM workflows in mind. Specifically, we should carefully manage and keep the cognitive load required to understand and contribute code to a project at a minimum.
Every package, or directory, should consist of several independently testable subsets of code, wherein each subset contains basically 3 files: shared.go for the package’s shared typedefs and globals, whereas x.go and x_test.go focus on a specific aspect of our functional logic, ideally just one public function per file. Sometimes we also have main_test.go supplying a TestMain function for setting up test environments (e.g. testcontainers).
Recently I started a brand new software project at work, so I had the opportunity to design the code organization starting from a clean slate. I’m currently exploring an extension to this AI TDD workflow for larger projects. The whole project code would need to be copied to the sandbox for execution, but sending the entire codebase to an LLM is impractical and distracts the model’s focus. Instead, we designate a specific package (subdirectory) that the LLM will work on at any given time, include a gomarkdoc-generated documentation for each dependency we think is helpful, and finally include a same-package example code (perhaps a closely-coupled entity’s finished implementation). The model will produce a function and a test, just like before, but this time we write the files in our intended subdirectory deep inside the sandbox to run the unit test.
With this pattern, not only do we limit the chance of introducing problematic code into production with test coverage by default, but we also encourage aggressive de-coupling and a unit test-first project structure. Because adding additional context to a model incurs some inference (and human-psychological) cost, we are constantly nudged towards maintaining our code as nice little chunks, each consuming only a small cognitive load to fully understand. Hopefully, this approach lets us end up with “deep” modules with rich functionalities but minimal surface area, because absent external forces, entropy always grows and logic scatters all over the place.
In closing, you should remember AI’s Bitter Lesson. There is a non-zero chance we wake up tomorrow to a major shift in AI architecture, eliminating the LLM limitations we talked about and rendering our efforts meaningless. So perhaps don’t start refactoring right away your 100k-Line-of-Code projects following this advice!